Introduction
Parquet
Installation
For detailed installation instructions, see the installation page.
Engine System
The parquet library supports a pluggable engine system with two implementations:
- PHP Engine (
PhpParquetEngine) — Pure PHP implementation. Works everywhere with no extra dependencies beyond optional compression extensions. - Arrow Engine (
ArrowParquetEngine) — Uses the arrow PHP extension for native Rust-powered performance. All compression codecs are built into the extension. - Adaptive Engine (
AdaptiveParquetEngine) — Default. Automatically selects Arrow if thearrowextension is loaded, otherwise falls back to PHP.
Engine Selection
By default, new Reader() and new Writer() use the adaptive engine:
<?php
use Flow\Parquet\Reader;
use Flow\Parquet\Writer;
// Adaptive engine: uses Arrow if ext-arrow is loaded, otherwise PHP
$reader = new Reader();
$writer = new Writer();
To explicitly choose an engine:
<?php
use Flow\Parquet\Reader;
use Flow\Parquet\Writer;
// Force Arrow engine (throws if ext-arrow is not loaded)
$reader = Reader::arrow();
$writer = Writer::arrow();
// Force PHP engine
$reader = Reader::php();
$writer = Writer::php();
Cross-Engine Compatibility
Files written by one engine can be read by the other. Both produce standard Apache Parquet files.
When to Use Each Engine
| Consideration | PHP Engine | Arrow Engine |
|---|---|---|
| Setup | No extra requirements | Requires ext-arrow |
| Performance | Good for small/medium datasets | Significantly faster for large datasets |
| Compression | Requires PHP extensions per codec | All codecs built-in |
| Nested types | Full Dremel support | Full support via Arrow |
| Recommended for | Environments without Rust | Production workloads |
What is Parquet
Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. Parquet is available in multiple languages including Java, C++, Python, etc... Now also in PHP!
Columnar Storage
Parquet stores data in a columnar format, but what does it means?
Row-based format:
| ID | Name | Age |
|---|---|---|
| 1 | Alice | 20 |
| 2 | Bob | 25 |
| 3 | Carol | 30 |
Column-based format:
| ID | 1 | 2 | 3 |
|---|---|---|---|
| Name | Alice | Bob | Carol |
| Age | 20 | 25 | 30 |
This approach has several advantages:
- Compression: Since data is stored in columns, it is naturally compressed better.
- I/O: When querying a subset of columns, we can skip reading the other columns. This is especially useful when the columns are large.
- Encoding: Different encoding schemes can be used for different columns, depending on the data type and the distribution of values.
- Data skipping: When querying a subset of rows, we can skip reading the other rows. This is especially useful when the rows are large.
- Reading selective columns: When querying a subset of columns, we can skip reading the other columns. This is especially useful when the columns are large.
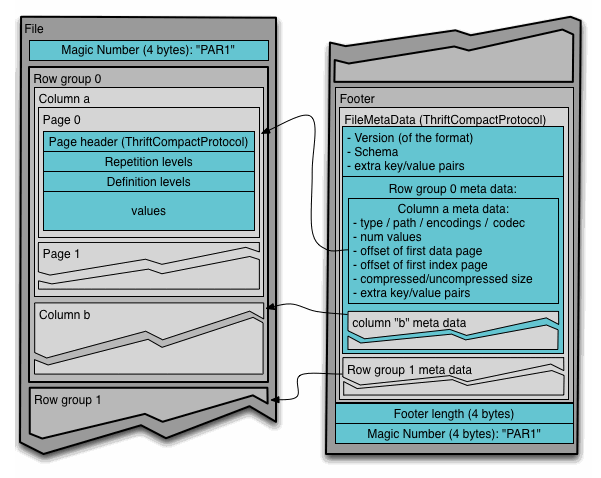
Parquet File Structure
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata (little endian)
4-byte magic number "PAR1"
Reading Parquet Files
The first thing we need to do is to create a reader.
use Flow\Parquet\Reader;
$reader = new Reader();
[!TIP]
new Reader()uses the adaptive engine. See Engine System for how to explicitly choose the Arrow or PHP engine.
The Reader accepts two arguments:
$byteOrder- by default set toByteOrder::LITTLE_ENDIAN$options- a set of options that can be used to configure the reader.
All available options are described in Option enum.
Please be aware that not all options are affecting reader.
Reader Options
INT_96_AS_DATETIME- default:true- if set totruethenINT96values will be converted toDateTimeobjects.
Reading a file
Once we have reader we can read a file.
use Flow\Parquet\Reader;
$reader = new Reader();
$file = $reader->read('path/to/file.parquet');
$file = $reader->readStream(\fopen('path/to/file.parquet', 'rb'));
At this point, nothing is read yet. We just created a file object.
There are several things we can read from parquet file:
ParquetFile::values(array $columns = [], ?int $limit = null, ?int $offset = null) : \GeneratorParquetFile::metadata() : MetadataParquetFile::schema() : Schema- shortcut forParquetFile::metadata()->schema()
Reading the whole file:
use Flow\Parquet\Reader;
$reader = new Reader();
$file = $reader->read('path/to/file.parquet');
foreach ($file->values() as $row) {
// do something with $row
}
Reading selected columns
use Flow\Parquet\Reader;
$reader = new Reader();
$file = $reader->read('path/to/file.parquet');
foreach ($file->values(["column_1", "column_2"]) as $row) {
// do something with $row
}
Pagination
[!NOTE] Paginating over parquet file is a bit tricky, especially if we want to keep memory usage low. To achieve the best results, we will need to play a bit with Writer options (covered later).
use Flow\Parquet\Reader;
$reader = new Reader();
$file = $reader->read('path/to/file.parquet');
foreach ($file->values(["column_1", "column_2"], limit: 100, offset: 1000) as $row) {
// do something with $row
}
Writing Parquet Files
Since parquet is a binary format, we need to provide a schema for the writer so it can know how to encode values in specific columns.
Here is how we can create a schema:
use Flow\Parquet\ParquetFile\Schema;
use Flow\Parquet\ParquetFile\Schema\FlatColumn;
use Flow\Parquet\ParquetFile\Schema\NestedColumn;
$schema = Schema::with(
FlatColumn::int64('id'),
FlatColumn::string('name'),
FlatColumn::boolean('active'),
FlatColumn::dateTime('created_at'),
NestedColumn::list('list_of_int', Schema\ListElement::int32()),
NestedColumn::map('map_of_int_string', Schema\MapKey::int32(), Schema\MapValue::string()),
NestedColumn::struct('struct', [
FlatColumn::int64('id'),
FlatColumn::string('name'),
FlatColumn::boolean('active'),
FlatColumn::dateTime('created_at'),
NestedColumn::list('list_of_int', Schema\ListElement::int32()),
NestedColumn::map('map_of_int_string', Schema\MapKey::int32(), Schema\MapValue::string()),
])
);
Once we have a schema, we can create a writer.
use Flow\Parquet\Writer;
$writer = new Writer();
[!TIP]
new Writer()uses the adaptive engine. UseWriter::arrow()orWriter::php()to explicitly select an engine. See Engine System.
and write our data:
$writer->write(
$path,
$schema,
[
[
'id' => 1,
'name' => 'Alice',
...
]
]
);
This approach will open a parquet file, create a group writer, write all data and close the file. It requires to keep whole dataset in memory which usually is not the best approach.
Writing data in chunks
Before we can write a batch of rows, we need to open a file.
$writer->open($path, $schema);
$writer->writeBatch([$row, $row]);
$writer->writeBatch([$row, $row]);
$writer->writeBatch([$row, $row]);
$writer->writeBatch([$row, $row]);
$writer->writeBatch([$row, $row]);
$writer->close();
We can also open a file for a resource:
$writer->openForStream($stream, $schema);
Writing a single row
$writer->open($path, $schema);
$writer->writeRow($row);
$writer->writeRow($row);
$writer->writeRow($row);
$writer->writeRow($row);
$writer->writeRow($row);
$writer->close();
[!WARNING] At this point, schema evolution is not yet supported. We need to make sure that schema is the same as the one used to create a file.
Writer Options
BYTE_ARRAY_TO_STRING- default:true- if set totruethenBYTE_ARRAYvalues will be converted tostringobjects.DICTIONARY_PAGE_MIN_CARDINALITY_RATION- default '0.4' - minimum ratio of unique values to total values for a column to have dictionary encoding.DICTIONARY_PAGE_SIZE- default:1Mb- maximum size of dictionary page.GZIP_COMPRESSION_LEVEL- default:9- compression level for GZIP compression (applied only when GZIP compression is enabled).PAGE_SIZE_BYTES- default:8Kb- maximum size of data page.ROUND_NANOSECONDS- default:false- Since PHP does not support nanoseconds precision for DateTime objects, when this options is set to true, reader will round nanoseconds to microseconds.ROW_GROUP_SIZE_BYTES- default:8Mb- maximum size of row group.ROW_GROUP_SIZE_CHECK_INTERVALdefault:1000- number of rows to write before checking if row group size limit is reached.VALIDATE_DATA- default:true- if set totruethen writer will validate data against schema.WRITER_VERSION- default1- tells writer which version of parquet format should be used.
Two most important options that can heavily affect memory usage are:
ROW_GROUP_SIZE_BYTESROW_GROUP_SIZE_CHECK_INTERVAL
Row Group Size defines pretty much how much data writer (but also reader) will need to keep in memory before flushing it to the file. Row group size check interval, defines how often writer will check if row group size limit is reached. If you set this value too high, writer might exceed row group size limit.
By default tools like Spark or Hive are using 128-512Mb as a row group size. Which is great for big data, and quick processing in memory but not so great for PHP.
For example, if you need to paginate over file with 1Gb of data, and you set row group size to 512Mb, you will need to keep at least 512Mb of data in memory at once.
A Much better approach is to reduce the row group size to something closer to 1Mb, and row grpu size check interval to what your default page size should be - like for example 100 or 500 (that obviously depends on your data)
This way you will keep memory usage low, and you will be able to paginate over big files without any issues. But it will take a little longer to write to these files, because writer has to flush and calculate statistic more frequently.
Unfortunately, there is no one size fits all solution here. You will need to play a bit with those values to find the best one for your use case.
Compressions
[!NOTE] When using the Arrow engine, all compression codecs are built into the native extension. The PHP compression extensions listed below are only required when using the PHP engine.
Parquet supports several compression algorithms.
BROTLI- supported if Brotli Extension is installedGZIP- supported out of the boxLZ4- supported if LZ4 Extension is installedLZ4_RAW- supported if LZ4 Extension is installedLZO- not yet supportedSNAPPY- supported - it's recommended to install Snappy Extension - otherwise php implementation is used that is much slower than extensionUNCOMPRESSED- supported out of the boxZSTD- supported if ZSTD Extension is installed
Obviously, compression is a trade-off between speed and size.
If you want to achieve the best compression, you should use GZIP or SNAPPY which is a default compression algorithm.
For not yet supported algorithms, please check our Roadmap to understand when they will be supported.
Per-Column Compression
You can specify different compression algorithms for individual columns using flat path notation. This allows fine-grained control over the compression strategy for optimal storage and performance.
When to Use Per-Column Compression
Different data characteristics require different compression strategies:
- Fast access columns (IDs, timestamps) - Use
UNCOMPRESSEDorLZ4for minimal decompression overhead - Categorical data (status, country codes) - Use
SNAPPYfor balanced compression with good performance - Text/JSON data (descriptions, metadata) - Use
ZSTDorBROTLIfor maximum compression - Numerical data - Use
LZ4orSNAPPYfor good compression with fast access - Archival columns - Use
ZSTDfor maximum compression when access speed is less critical
Basic Per-Column Compression
use Flow\Parquet\{Writer, Options, Option};
use Flow\Parquet\ParquetFile\{Schema, Compressions};
use Flow\Parquet\ParquetFile\Schema\FlatColumn;
$schema = Schema::with(
FlatColumn::int64('user_id'),
FlatColumn::string('status'),
FlatColumn::string('description'),
FlatColumn::float('price')
);
$options = Options::default()->set(Option::COLUMNS_COMPRESSIONS, [
'user_id' => Compressions::UNCOMPRESSED, // Fast access for frequent queries
'status' => Compressions::SNAPPY, // Balanced compression for enum-like data
'description' => Compressions::ZSTD, // Maximum compression for text data
'price' => Compressions::LZ4 // Fast compression for numeric data
]);
// Global compression serves as fallback for unspecified columns
$writer = new Writer(compressions: Compressions::GZIP, options: $options);
Nested Column Compression
For nested structures, use the same flat path notation as column encodings:
use Flow\Parquet\ParquetFile\Schema\{NestedColumn, ListElement, MapKey, MapValue};
$schema = Schema::with(
NestedColumn::struct('user', [
FlatColumn::int64('id'),
FlatColumn::string('name'),
NestedColumn::struct('address', [
FlatColumn::string('street'),
FlatColumn::string('city'),
FlatColumn::string('country')
])
]),
NestedColumn::list('tags', ListElement::string()),
NestedColumn::map('metadata', MapKey::string(), MapValue::string())
);
$options = Options::default()->set(Option::COLUMNS_COMPRESSIONS, [
// Struct fields - direct access
'user.id' => Compressions::UNCOMPRESSED, // Primary key - fast access
'user.name' => Compressions::SNAPPY, // Balanced for names
'user.address.street' => Compressions::ZSTD, // High compression for addresses
'user.address.city' => Compressions::LZ4, // Fast for frequently queried cities
'user.address.country' => Compressions::SNAPPY, // Balanced for country codes
// List elements - note the '.list.element' suffix
'tags.list.element' => Compressions::BROTLI, // High compression for tags
// Map key/value pairs - note the '.key_value.key/value' suffix
'metadata.key_value.key' => Compressions::LZ4, // Fast access for metadata keys
'metadata.key_value.value' => Compressions::ZSTD // Max compression for metadata values
]);
Performance-Optimized Strategies
Query-Optimized Strategy:
$options = Options::default()->set(Option::COLUMNS_COMPRESSIONS, [
// Frequently queried columns - prioritize speed
'user_id' => Compressions::UNCOMPRESSED,
'created_at' => Compressions::LZ4,
'status' => Compressions::SNAPPY,
// Analytical columns - prioritize compression
'analytics_payload' => Compressions::ZSTD,
'raw_data' => Compressions::BROTLI,
// Balanced approach for mixed usage
'category' => Compressions::SNAPPY,
'description' => Compressions::GZIP
]);
Storage-Optimized Strategy:
$options = Options::default()->set(Option::COLUMNS_COMPRESSIONS, [
// Only critical columns use fast compression
'id' => Compressions::LZ4,
// Everything else maximizes compression
'content' => Compressions::ZSTD,
'metadata' => Compressions::BROTLI,
'tags' => Compressions::GZIP,
'attributes' => Compressions::ZSTD
]);
Combined Compression and Encoding Strategy
You can combine per-column compression with custom encodings for optimal results:
$options = Options::default()
->set(Option::COLUMNS_COMPRESSIONS, [
'user_id' => Compressions::UNCOMPRESSED, // Fast primary key access
'status' => Compressions::SNAPPY, // Balanced for enum data
'metadata' => Compressions::ZSTD // Max compression for JSON
])
->set(Option::COLUMNS_ENCODINGS, [
'user_id' => Encodings::DELTA_BINARY_PACKED, // Efficient encoding for sequential IDs
'status' => Encodings::RLE_DICTIONARY, // Dictionary for repeated values
'metadata' => Encodings::PLAIN // No encoding overhead for compressed data
]);
Compression Selection Guidelines
| Data Type | Characteristics | Recommended Compression | Use Case |
|---|---|---|---|
| Primary Keys | Sequential integers, frequent queries | UNCOMPRESSED or LZ4 |
Fast joins and lookups |
| Status/Categories | Low cardinality, repeated values | SNAPPY |
Balanced performance |
| Timestamps | Sequential, frequently filtered | LZ4 |
Fast time-based queries |
| Text Content | High variance, large size | ZSTD or BROTLI |
Storage optimization |
| JSON/Metadata | Complex nested data | ZSTD |
Maximum compression |
| Numerical Data | Calculations, aggregations | SNAPPY or LZ4 |
Fast mathematical operations |
| Archive Data | Rarely accessed | ZSTD or BROTLI |
Long-term storage |
Performance vs. Compression Trade-offs
Compression Ratio (Best to Worst):
ZSTD- Best compression, slower decompressionBROTLI- Excellent compression, moderate speedGZIP- Good compression, widely supportedSNAPPY- Balanced compression and speed (default)LZ4- Fast compression/decompression, moderate ratioUNCOMPRESSED- No compression overhead, largest size
Decompression Speed (Fastest to Slowest):
UNCOMPRESSED- No decompression neededLZ4- Very fast decompressionSNAPPY- Fast decompression (good balance)GZIP- Moderate decompression speedBROTLI- Slower decompressionZSTD- Configurable, generally slower for high compression
Column Encodings
Parquet supports various column encoding algorithms that can significantly impact file size and query performance. You can specify custom encodings for individual columns using flat path notation.
Available Encodings
PLAIN
The default encoding that stores values as-is without any compression scheme.
When to use:
- Small datasets where compression overhead isn't justified
- Columns with high cardinality and random distribution
- When you need maximum compatibility with other Parquet readers
Supported types: All column types
use Flow\Parquet\{Options, Option};
use Flow\Parquet\ParquetFile\Encodings;
$options = Options::default()->set(Option::COLUMNS_ENCODINGS, [
'description' => Encodings::PLAIN,
'uuid' => Encodings::PLAIN
]);
RLE_DICTIONARY
Run Length Encoding with Dictionary compression. Values are stored in a dictionary and replaced with indices.
When to use:
- Columns with low cardinality (many repeated values)
- String columns with repeated categories (status, country, department)
- Enumeration-like data
- Significant file size reduction (often 50-90% smaller)
Supported types: All types except FIXED_LEN_BYTE_ARRAY
$options = Options::default()->set(Option::COLUMNS_ENCODINGS, [
'status' => Encodings::RLE_DICTIONARY, // 'active', 'inactive', 'pending'
'country_code' => Encodings::RLE_DICTIONARY, // 'US', 'UK', 'DE', 'FR'
'department' => Encodings::RLE_DICTIONARY // 'engineering', 'sales', 'marketing'
]);
DELTA_BINARY_PACKED
Delta encoding with binary packing for integer columns. Stores differences between consecutive values.
When to use:
- Sequential or monotonic integer data (IDs, timestamps, counters)
- Time series data with incremental values
- Can achieve 70-95% compression for sequential data
Supported types: Only INT32 and INT64
$options = Options::default()->set(Option::COLUMNS_ENCODINGS, [
'user_id' => Encodings::DELTA_BINARY_PACKED, // 1, 2, 3, 4, 5...
'timestamp_ms' => Encodings::DELTA_BINARY_PACKED, // 1634567890123, 1634567890124...
'order_number' => Encodings::DELTA_BINARY_PACKED // Sequential order IDs
]);
Using Custom Encodings
Basic Column Encoding
use Flow\Parquet\{Writer, Options, Option};
use Flow\Parquet\ParquetFile\{Schema, Compressions, Encodings};
use Flow\Parquet\ParquetFile\Schema\FlatColumn;
$schema = Schema::with(
FlatColumn::int64('user_id'),
FlatColumn::string('status'),
FlatColumn::string('description')
);
$options = Options::default()->set(Option::COLUMNS_ENCODINGS, [
'user_id' => Encodings::DELTA_BINARY_PACKED, // Sequential IDs
'status' => Encodings::RLE_DICTIONARY, // Limited set of values
'description' => Encodings::PLAIN // High variance text
]);
$writer = new Writer(compressions: Compressions::SNAPPY, options: $options);
Nested Column Encoding (Flat Path Notation)
For nested structures, use dot notation to specify the exact column path. The flat path follows Parquet's internal structure conventions:
Flat Path Patterns:
- Struct fields:
parent.field_name - List elements:
list_name.list.element - Map keys:
map_name.key_value.key - Map values:
map_name.key_value.value
use Flow\Parquet\ParquetFile\Schema\{NestedColumn, ListElement, MapKey, MapValue};
$schema = Schema::with(
NestedColumn::struct('user', [
FlatColumn::int64('id'),
FlatColumn::string('name'),
NestedColumn::struct('address', [
FlatColumn::string('street'),
FlatColumn::string('city'),
FlatColumn::string('country')
])
]),
NestedColumn::list('tags', ListElement::string()),
NestedColumn::map('metadata', MapKey::string(), MapValue::string())
);
Understanding Flat Paths:
// STRUCT: Direct field access with dot notation
'user.id' // user struct → id field
'user.name' // user struct → name field
'user.address.street' // user struct → address struct → street field
'user.address.city' // user struct → address struct → city field
'user.address.country' // user struct → address struct → country field
// LIST: Always includes intermediate '.list.element' structure
'tags.list.element' // tags list → list wrapper → element (the actual string values)
// MAP: Always includes intermediate '.key_value' structure
'metadata.key_value.key' // metadata map → key_value wrapper → key (string keys)
'metadata.key_value.value' // metadata map → key_value wrapper → value (string values)
Applying Custom Encodings:
$options = Options::default()->set(Option::COLUMNS_ENCODINGS, [
// Struct fields - direct access
'user.id' => Encodings::DELTA_BINARY_PACKED,
'user.name' => Encodings::RLE_DICTIONARY,
'user.address.street' => Encodings::PLAIN,
'user.address.city' => Encodings::RLE_DICTIONARY,
'user.address.country' => Encodings::RLE_DICTIONARY,
// List elements - note the '.list.element' suffix
'tags.list.element' => Encodings::RLE_DICTIONARY,
// Map key/value pairs - note the '.key_value.key/value' suffix
'metadata.key_value.key' => Encodings::RLE_DICTIONARY,
'metadata.key_value.value' => Encodings::PLAIN
]);
Complex Nested Example:
// Complex nested structure with lists of structs and maps
$schema = Schema::with(
NestedColumn::list('orders', ListElement::structure([
FlatColumn::int64('order_id'),
FlatColumn::string('status'),
NestedColumn::map('attributes', MapKey::string(), MapValue::string())
]))
);
$options = Options::default()->set(Option::COLUMNS_ENCODINGS, [
// List of structs: list_name.list.element.field_name
'orders.list.element.order_id' => Encodings::DELTA_BINARY_PACKED,
'orders.list.element.status' => Encodings::RLE_DICTIONARY,
// Map inside list element: list_name.list.element.map_name.key_value.key/value
'orders.list.element.attributes.key_value.key' => Encodings::RLE_DICTIONARY,
'orders.list.element.attributes.key_value.value' => Encodings::PLAIN
]);
Mixed Encoding Strategy
$options = Options::default()->set(Option::COLUMNS_ENCODINGS, [
// High cardinality sequential data
'order_id' => Encodings::DELTA_BINARY_PACKED,
'created_timestamp' => Encodings::DELTA_BINARY_PACKED,
// Low cardinality categorical data
'order_status' => Encodings::RLE_DICTIONARY,
'payment_method' => Encodings::RLE_DICTIONARY,
'shipping_country' => Encodings::RLE_DICTIONARY,
// High variance descriptive data
'customer_notes' => Encodings::PLAIN,
'product_description' => Encodings::PLAIN
]);
Encoding Compatibility
| Encoding | INT32/INT64 | BYTE_ARRAY | BOOLEAN | FLOAT/DOUBLE | FIXED_LEN_BYTE_ARRAY |
|---|---|---|---|---|---|
| PLAIN | ✅ | ✅ | ✅ | ✅ | ✅ |
| RLE_DICTIONARY | ✅ | ✅ | ✅ | ✅ | ❌ |
| DELTA_BINARY_PACKED | ✅ | ❌ | ❌ | ❌ | ❌ |
Performance Guidelines
- Analyze your data first - Check cardinality and distribution patterns
- Use RLE_DICTIONARY for categorical data - Countries, statuses, departments
- Use DELTA_BINARY_PACKED for sequential integers - IDs, timestamps, counters
- Use PLAIN for high-variance data - Descriptions, UUIDs, random data
- Test different combinations - Measure file size and query performance
- Consider query patterns - Frequently filtered columns benefit from dictionary encoding
Adapters
Libraries
Symfony
Bridges
Contributors
Join us on GitHub






















